Agent IA de qualité des données
Alno
Il repère doublons et anomalies dans un fichier maître et propose des corrections justifiées par des règles, mais l'humain valide chaque écriture. Aucune valeur inventée.
- 100 %
- des anomalies détectées (7/7)
- 100 %
- des écritures validées par un humain
- 0,25 $
- par analyse
- 3/3
- exécutions identiques
Mesuré sur la démo : moyenne sur 3 exécutions indépendantes, 7 anomalies injectées, reproductibles.
- Durée
- 2 semaines
- Mon rôle
- Projet démo, vitrine de compétence
- Statut
- Démonstrateur fonctionnel et mesuré (vidéo de démo disponible)
- IA de confiance
- Qualité de données
- Validation humaine
Le contexte
Alno est un projet démo que j’ai construit pour démontrer une compétence, pas une mission client : un agent IA de qualité de données, mesuré et reproductible.
Les fichiers maîtres (clients, fournisseurs, produits) dérivent avec le temps : doublons accumulés au fil des saisies, formats incohérents, codes pays en toutes lettres, numéros de TVA mal renseignés. Cible : les PME B2B (5 à 50 salariés) qui gèrent un référentiel fournisseurs, clients ou un catalogue produits.
Le problème
Nettoyer ces fichiers à la main est lent, risqué, et n’arrive qu’une fois tous les quelques ans, quand ça arrive.
La solution, en bref
Une console en trois temps : l’agent analyse le fichier et détecte doublons, formats incohérents et champs mal formés ; chaque proposition passe en revue dans une file de validation structurée (valeur actuelle, valeur proposée, raisonnement, règle invoquée) ; l’utilisateur approuve ou rejette, une par une. L’agent n’a aucun accès en écriture : le chemin d’écriture n’est déclenché que par une action humaine. Une garantie de l’architecture, pas un réglage.
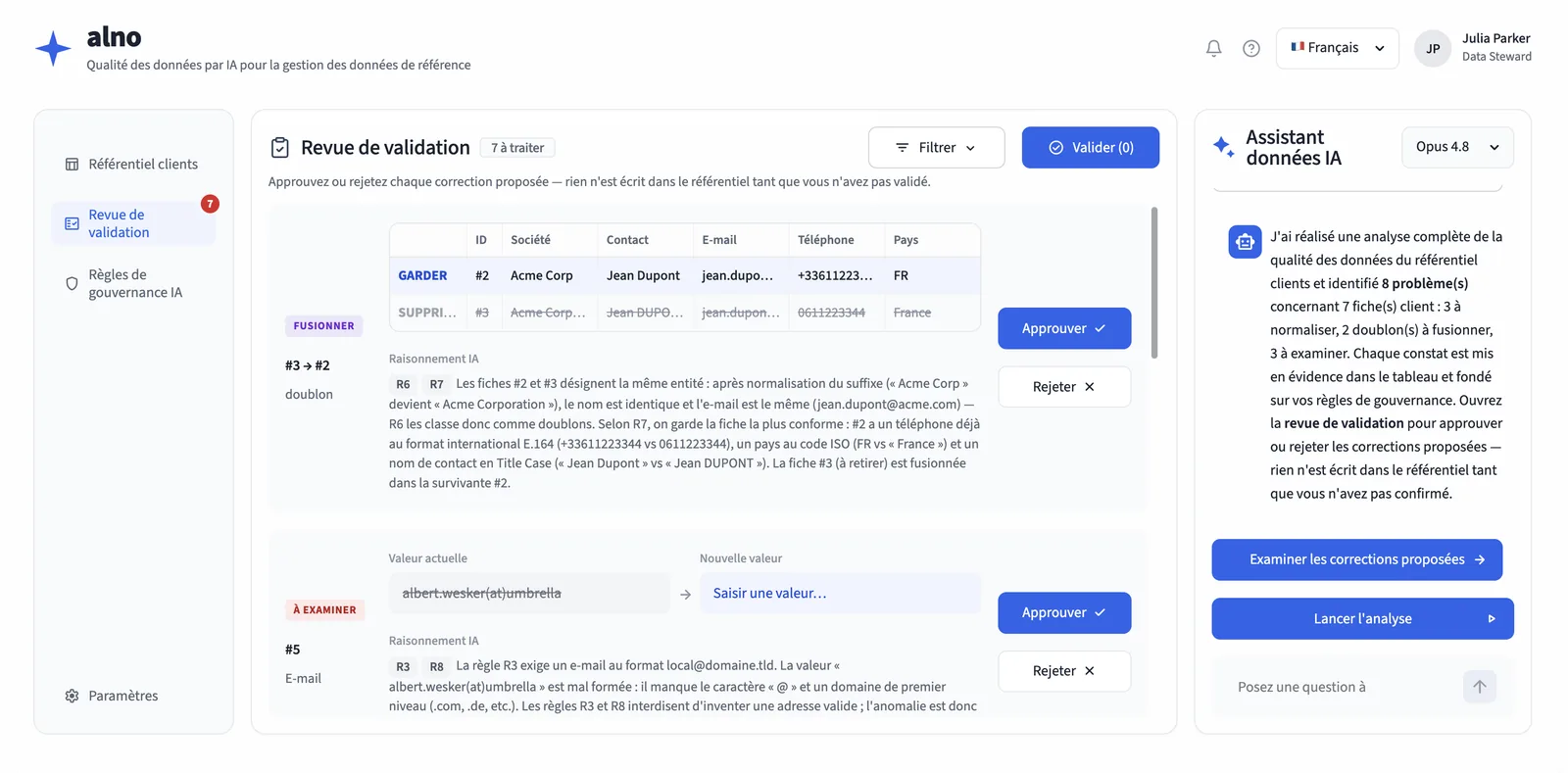
Principe clé : l’agent n’invente jamais une valeur qu’il ne peut pas dériver d’un enregistrement ou d’une règle. Face à une donnée manquante ou ambiguë, il signale au lieu de deviner.
Le moteur est standard, vos données sont des paramètres : colonnes, libellés métier et règles de gouvernance se reconfigurent en quelques minutes, du référentiel fournisseurs au catalogue produits. Le tout est construit sur le SDK Anthropic (Claude), avec une boucle agentique maîtrisée de bout en bout.
Le résultat
En clair : sur les tests, l’agent a repéré 100 % des anomalies sans jamais inventer une seule valeur, et chaque correction a exigé une validation humaine.
Ce que ça vaut pour une PME : un référentiel dédoublonné et normalisé en quelques minutes, chaque correction tracée et validée, là où un nettoyage manuel équivalent mobilise plusieurs jours-homme et n’arrive qu’une fois tous les quelques ans.
Envie d’aller plus loin ? Les mesures détaillées (fidélité, latence, coût par modèle), les choix structurants et la feuille de route sont dans l’étude de cas complète, à demander ci-dessous.
Recevoir l'étude de cas complète
Vous avez ici l'essentiel. L'étude de cas complète (PDF) détaille la démarche, les choix structurants et les résultats mesurés. Je vous l'envoie par e-mail.
Vous préférez parler directement de votre situation ? Me contacter.